Lecture 19 Database Logging
Crash Recovery
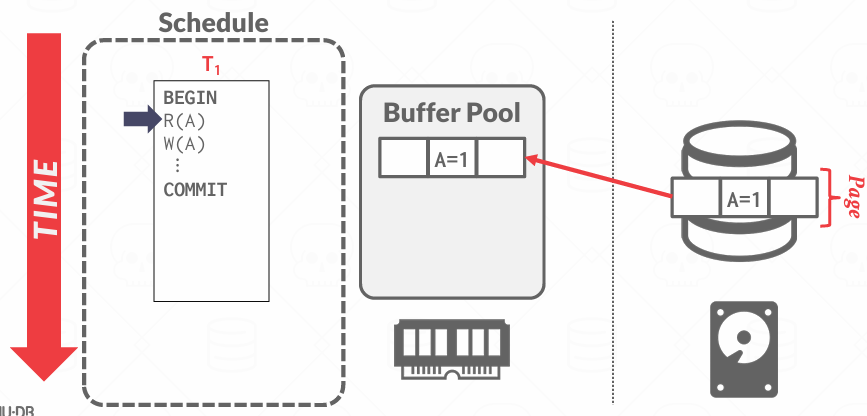
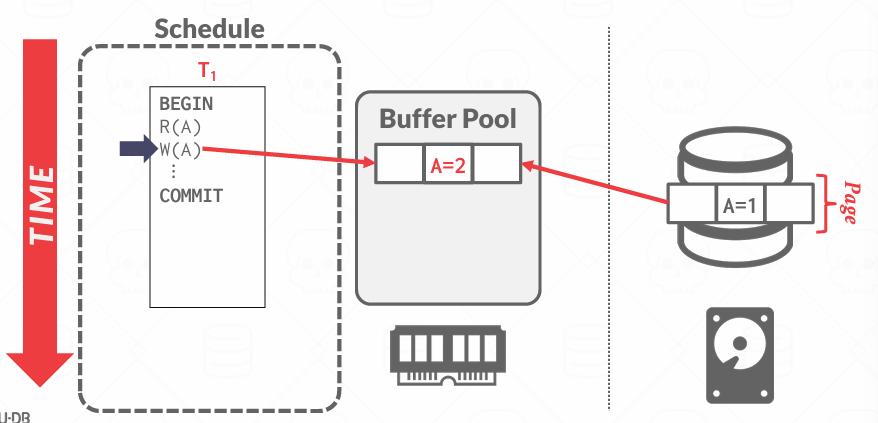
到了COMMIT的时候做什么?
为了确保持久性,我们可以坚持将任何已作出的更改推送磁盘,但是速度非常慢
假设我们拥有其他协议,这些协议在提交时不要求我们将所有内容刷新到磁盘,因为该事务可能设计了上十亿条数据
假设COMMIT的时候停电了, 或者有人意外清除了内存,会发生什么?
我们COMMIT了事务,但是变更只存在于缓冲池中,我们会丢失这些变更
我们需要获取原子性和持久性的组件
Today's Agenda
- Failure Classification: 讨论故障发生的原因
- Buffer Pool Policies: 缓冲池策略 -- 正是我们需要采用新技术的原因所在
- Shadow Paging: 一种机制,影子分页,跟踪所做更改 == bad ideas
- Write-Ahead Log: 预写日志,跟踪所做更改
- Logging Schemes: 日志方案, 了解在日志中应记录哪些信息
- Checkpoints: 检查点机制
Storage Types
- Volatile Storage
- Non-Volatile Storage
- Stable Storage
之前我们提到易损失性和不易损失性的存储, 在Lecture3就提到了
但是教科书中还提到了一种Stable Storage(稳定性存储), 它基本上能在所有的可能得故障场景中幸存下来,虽然这种理论上的存储并不存在,但我们可以通过所做的每件事进行复制来接近它。
一种提到的方法是复制磁盘,并使用分布式事务协议同步副本,后面的课会讲到,今天不会讲
Failure Classification
- Type 1: Transaction Failures
- Type 2: System Failures
- Type 3: Storage Media Failures
Transcation Failures
事务为什么会失败?
Logical Errors
首先可能是因其中存在逻辑错误而失败, 比如我更新了一条数据,完整性约束失败了就会中止事务
Internal State Erros
另一种可能是所执行的操作本身没有问题,但与另一个交易发生了死锁
总之,事务可能因多种原因失败,而这些都将纳入我们所讨论的原子性和持久性范畴,因为一个已失败的事务可能已经开始了某些变更操作,我们不得不撤销所有的这些更改
System Failures
SoftWare Failure
系统可能因软件故障而崩溃,此时部分工作已经完成,但事务尚未提交,或者事务已经提交,变更仍存在缓冲池中
Hardware Failure
Storage Media Failure
存储介质可能发生故障 比如我们认为数据已经写入磁盘, 但事实上并未成功写入 -- 数据已写入,但哪里的位元发生了损坏
我们需要其他类型的机制与复制一起应对这一问题,
我们假定有其他机制来解决这个问题,所以我们将不再进行讨论
Observation
作为数据库系统,我们需要确保已提交事务的变更能够安全存入稳定存储,同时避开任何部分变更的残留
有两个关键机制来实现这一点
- Undo(撤销): 即将某些内容放入了稳定存储, 这些更改是一个事务,但由于事务失败或者前面讨论的其他故障,该事务被中止了, 就需要撤销我们的操作
- Redo(重做): 即已提交的事务做的更改仅存在于缓冲池中,但该事务已经提到
Buffer Pool Policies
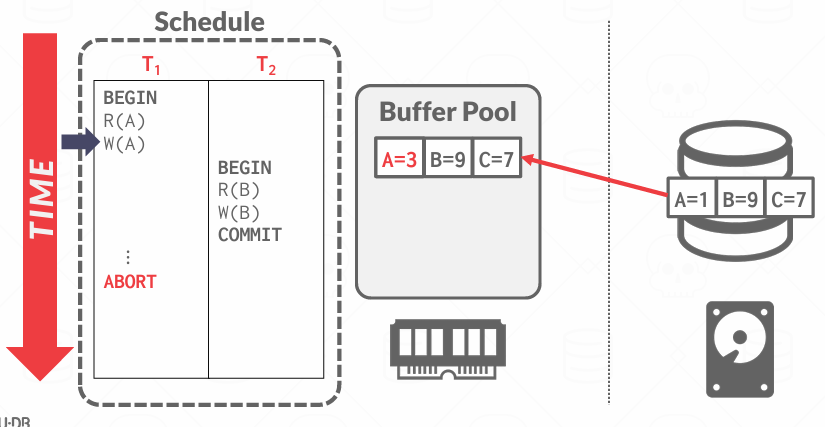
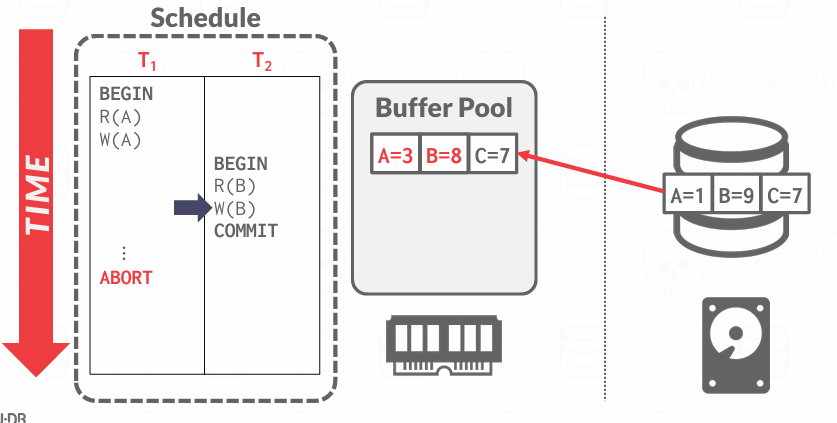
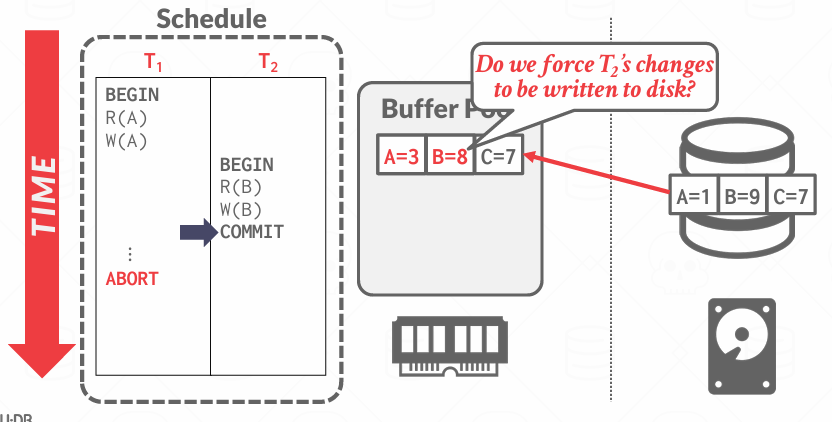
如果事务T2提交了,我们该如何处理?
如果我们决定将该页面刷新到磁盘以确保T2的更改持久化, 那我们会携带上T1对A的更改,但T1对A的结果尚未确定
会有各种各样的方案,但基本的思想是,因为他们都在同一页上,缓冲池能在页面内移动数据,某一给定页面可能因多个处于不同状态的事务而发生变更,必须确保在此场景下系统正常工作
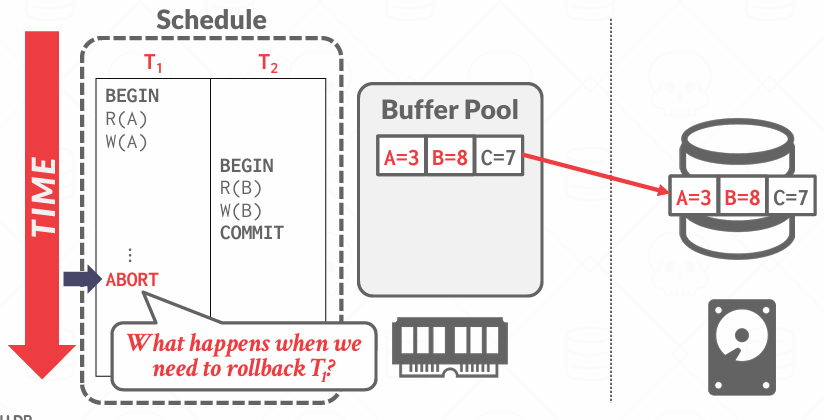
Steal Policy
我们在编写缓冲池时采用了LRU-K策略,而且我们在Project中的K=2, 这为缓冲管理器提供了很多自由 -- LRU-K能够跟踪页面的使用情况,并在需要驱逐时决定何时踢出某些内容。唯一的规定是,如果一个页面被锁定(pin),即有人正在使用它,就不能被踢出,但如果一个页面未被锁定,那么它可能是脏页,我就可以将其踢出,
为了获得缓冲池的最大性能和空间利用率,意味着即使页面有脏变更,我也允许将其踢出。
Steal Policy允许缓冲池管理器获取未加锁的页面并将其刷新到磁盘,即使页面是脏的,且该脏页所属的事务尚未提交。
所以说,未提交的更改会被写入稳定存储,这在steal策略下是允许的
而No-steal就是说除了锁定的页面,正在运行的事务的页面也没法窃取, 使用no-steal策略, 不仅并发程度低, buffer pool也很快会满 可能会导致死锁
Force Policy
提交时刻,我该如何操作的问题
在提交时刻,如果我声明正在提交的事务所做的所有更改必须在提交前强制写入磁盘,我们将获得持久性,但这样的成本会很高,因为可能会有大量的更改需要刷新
Force: 就是上面说的 强加所有的修改都写入
No-Force: 不要这样,寻求一种更高效的提交方式,并以不同的方法应对可能发生的负面情况, 这便是日志记录发挥作用的地方
Steal Policy + Force Policy 组合
可以变成一个四象限图了
No-Steal + Force
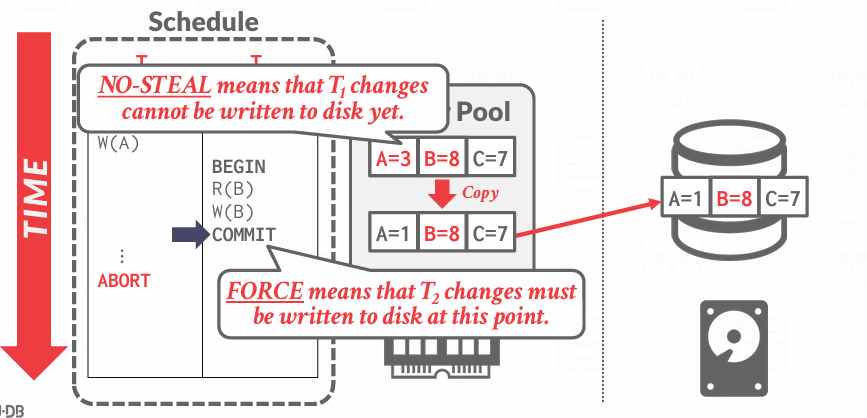
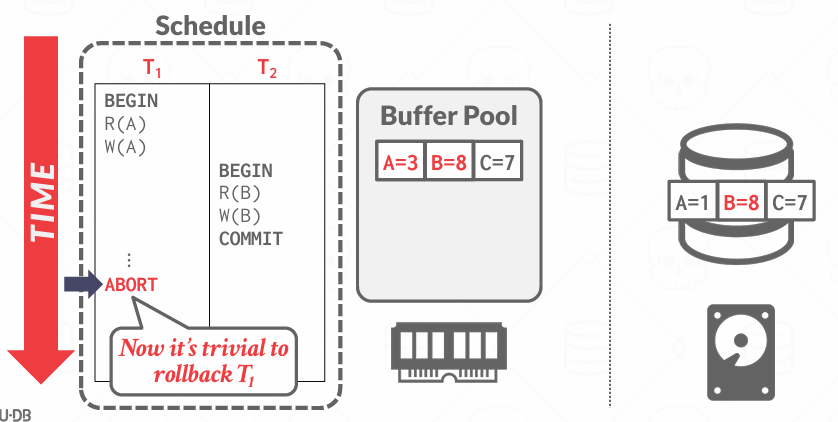
最简单的实现方案
- 不需要UNDO: 因为No-Steal, 未提交的事务从来没有写入磁盘, 所以不用担心撤销更改
- 不需要REDO: 因为是FORCE, 在提交的时候就已经把所有写入磁盘, 系统崩溃也不需要重做
但是这种策略有一个重大缺点: 事务的所有修改必须在内存中等待直到提交, 所以如果事务修改的数据太多,就会一直堆在内存中,如果超过了内存,就出问题了 -- 这是No-Steal带来的 -- 比如需要改所有page的一个字段 那就要把所有的page都放入内存 而且在commit之前没法替换出去
所以我们要寻求一种相反的方法,高性能的方案,就是实现STEAL, NO-FORCE的方案
Shadow Paging
随着我们开始进行更改,我们将不得不跟踪我们所做的更改,并据此进行工作。
所以我们需要记录从何处回退,或确保数据已经写入磁盘
有两种技术,前面today's agenda的时候已经介绍过了,一种是Shadow Paging(影子分页) -- bad idea, No one does it.但这是人们意识到需要恢复协议时所做的第一件事, 但是值得去了解一下
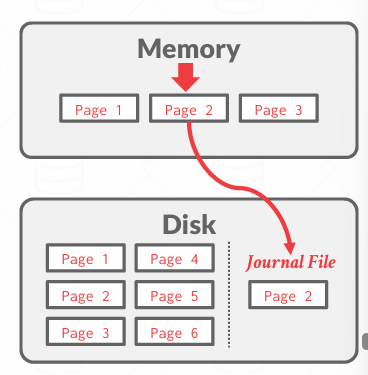
还是之前的那个例子: 两个事务的变更发生在同一个页面上,但这个问题还有一个更大的版本,即我有一些列变更需要处理,而影子分页实质上要求我们记录变更前后的版本
影子分页是一种不使用日志的事务恢复机制,核心思想是: 当事务修改数据时,不直接修改磁盘上的原始数据页(master page),而是创建一个新的“影子页(shadow page)”副本进行修改。只有当事务提交时,才原子性地切换指针,使“影子页”变成新的“主数据”。
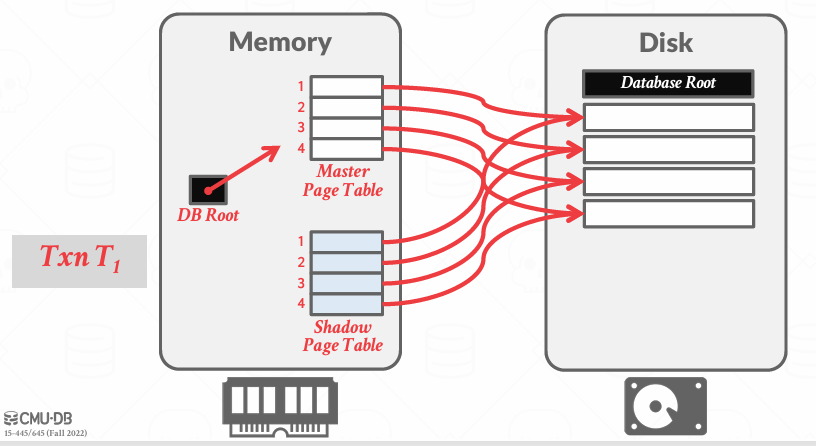
一种实现的方式是维护一个方案,记录我在四盘上的所有页面,并在内容中维护一个类似操作系统的page table, 在这里叫 master page table (主页表), 但是并不复杂,是一个pointer对应着Disk中的Page.
当事务到来时,他讲制作该page table的副本,可以有效的将其视为通过复制得到的快照, 叫Shadow Page Table.
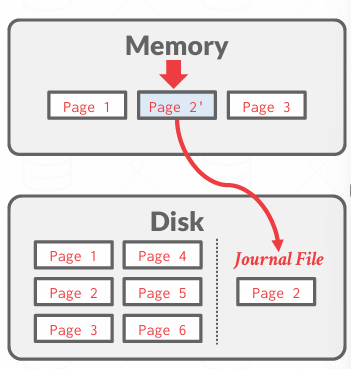
当事务更新的时候,更新的Shadow Page Table的内容,并在Disk中创建一个新副本,叫做影子副本
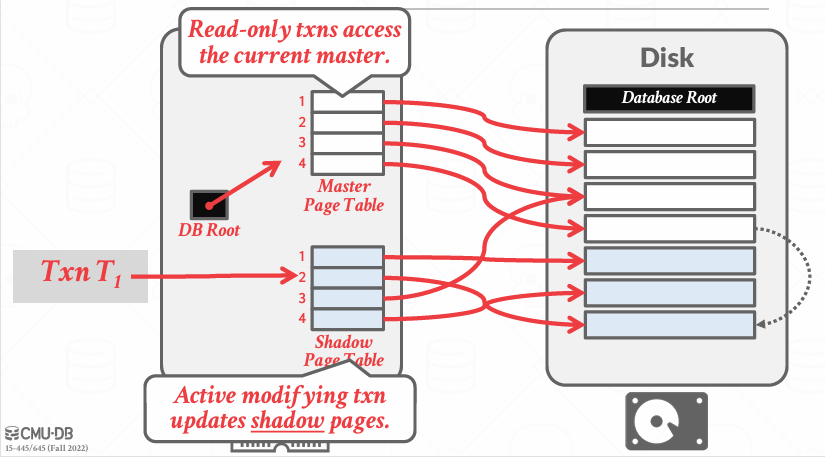
当提交的时候
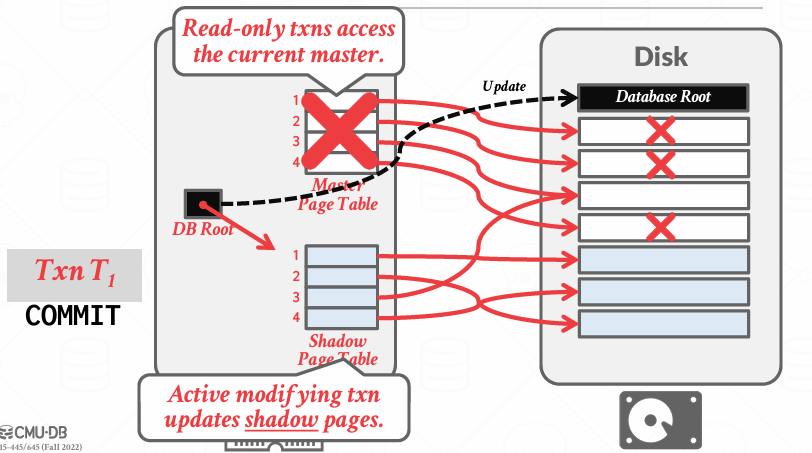
但这并不是一个好的方法,更优的方法是我们即将要讨论的基于预写日志协议的方案
Shdow Paging的缓冲策略就是 NO-STEAL + FORCE, 所以就像前面分析的一样,不用UNDO,不用REDO
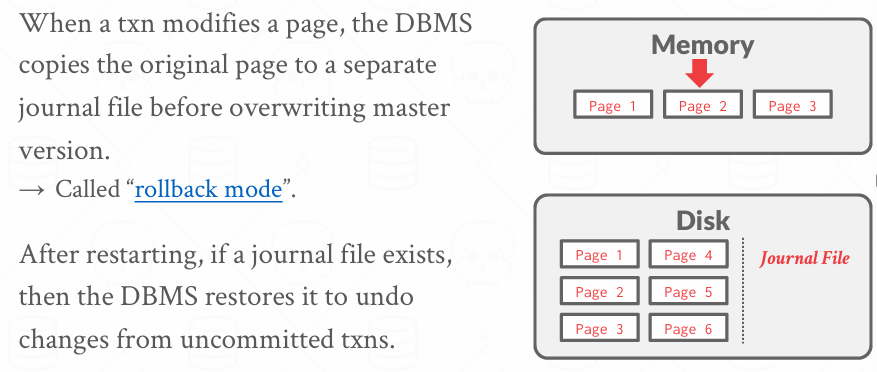
SQLite在过去用的是类似Shadow Page的一种方法, 后来转向了Write-Ahead Logging(预写日志)
Write-Ahead Log
Write-Ahead Log是实现恢复协议基础框架的方式
与最简单的方案相反,这里采用的是最困难的方案,STEAL + NO-FORCE. 为此,我们需要去记录正在进行的变更,并再用两种不同的方式利用这些变更
我们将创建一个名为日志文件的东西,注意啊,不是日志结构文件系统
我们会把日志信息存在数据库的log file中,log file是一个独立的文件,我们会创建log records(日志记录), 他们将在缓冲池中以page的形式创建,最终刷新到日志文件中
WAL是说,数据库中,任何数据页被写入磁盘之前,必须把它的修改记录写入日志文件 , 这样,即使系统崩溃,也能通过日志进行UNDO(撤销未提交事务)和REDO(重做已提交但尚未写盘的数据)来回复一致性, 所以 日志文件一般会存储在stable storage上, 这样断电也不会消失

这里提到了前面说的四个象限图
在Force方面,Force意味着对于每个更新都要将更新过的页面刷新到磁盘上,这意味着已提交的事务是持久的,其变更已经储存在了磁盘上,因此,对于已提交的事务,可以说已经满足了D(持久性),但这会导致响应时间交叉
对于No-Steal方面,No-Steal指缓冲区管理器不能从仍在工作的事务中取走页面,这对于批量事务是有效的,因为他们的变更最终会被写入磁盘,但是这会导致吞吐量较低,因为缓冲区管理器几乎没有自由度来进行页面置换和执行替换策略了
所以,我们真正需要的是No-Force, 对于No-Force, 我们的关注点在于提交时刻并不要求脏页必须刷新的磁盘, 而是利用LRUK,在需要往外替换的时候如果是脏页写回磁盘就好了。但是如果在写回Disk之前就崩溃了怎么办,这就需要我们通过日志记录一些东西,然后如果崩溃的话可以恢复 也就是要有REDO
除此之外,我们希望使用Steal策略,只要没有被pin, 就算事务未完成也可以被置换出去,这意味着可能事务没有执行完我也可以把修改过的内容写入Disk. 所以问题就是如果已经置换出去了,写入Disk了 事务终止了,怎么办,这就需要通过日志记录一些东西,来UNDO这些这些更改
我们需要一个基本的协议,也就是Write-Ahead Logging
这之前我们学过的协议中,有一个时刻是宣布事务的状态从active转为commit,而这个神奇的时刻就是有WAL决定的
WAL的核心规则是: 日志先于数据写盘 -- 这是一切的基础
所以说假如我想驱逐page13, buffer pool Manager会通知Log Manager, 让Log Manager先行写入所有的log, 然后再进行驱逐,当然这个过程仅限于脏页,如果是干净页面,无需与log manager交谈
WAL Protocol
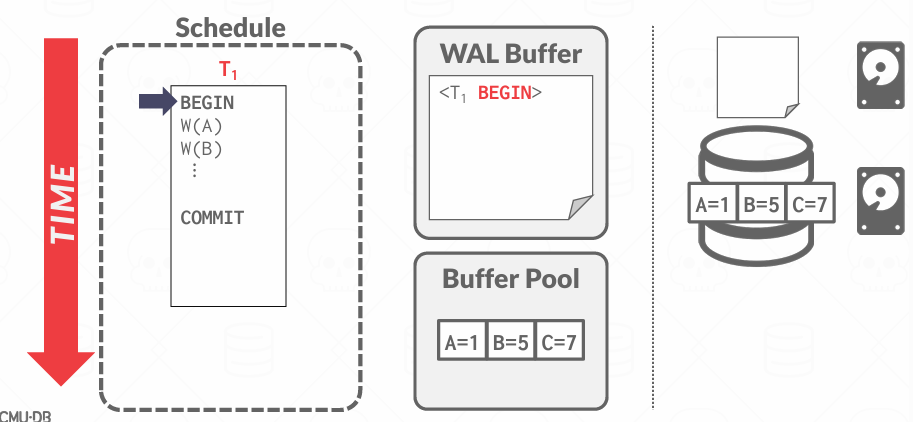
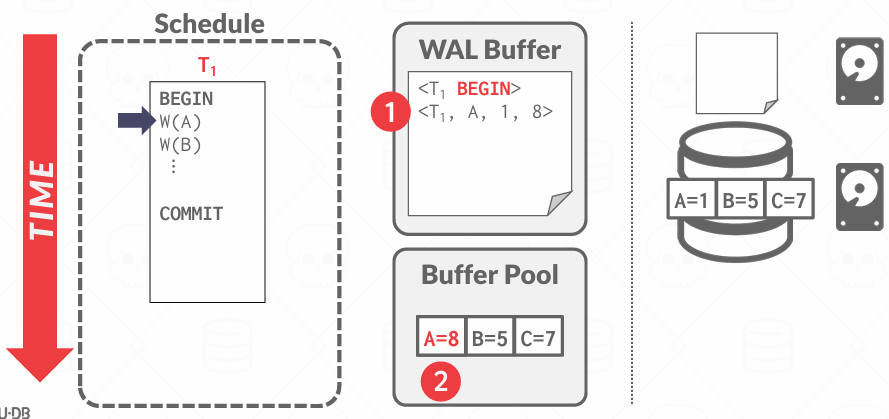
当一个事务开始执行,数据库就会在日志中写入一条 <BEGIN T1> 记录,用来标记事务的起点。
如果崩溃的时候看到BEGIN但没有COMMIT, 说明事务是未完成的,要UNDO
但事务要提交的时候,要先写入一条<COMMIT T1>日志, 表示事务逻辑上已经提交了,然后必须确保日志文件中的所有相关记录都已经写入磁盘,当日志全部落盘之后,数据库才会返回提交成功的信息
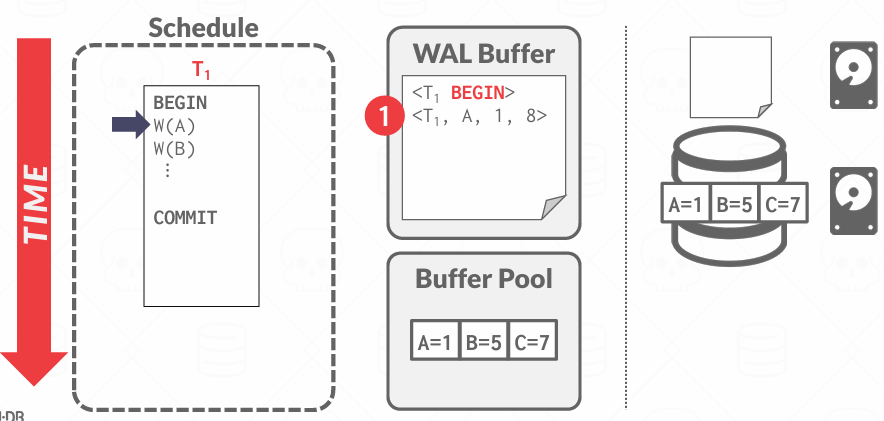
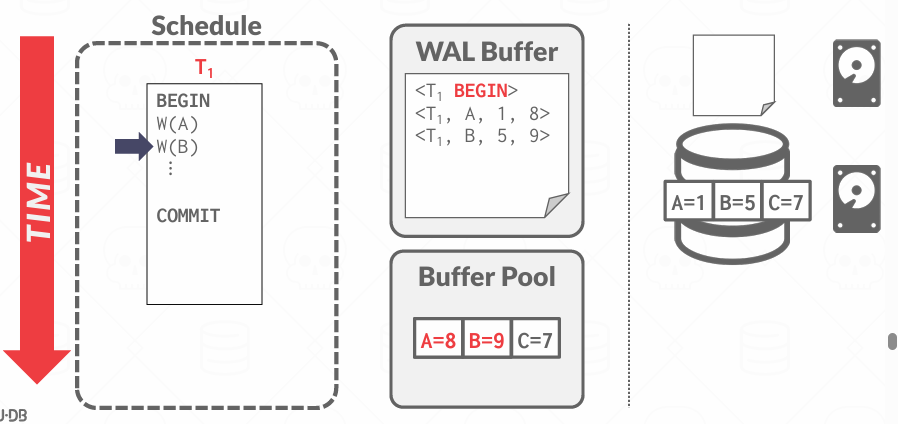
每条日志记录比如 <UPDATE T1, A, old=100, new=150>)记录的是一次对某个对象(数据项)的更改,日志记录包括:
- Transaction ID: 那个事务做的更改
- Object ID: 哪个对象被修改, 比如表中的哪一行, 哪一页或者哪个字段
- Before Value(UNDO): 修改前的值,用于撤销操作
- After Value(REDO): 修改后的值,如果事务提交但未来得及写盘 崩溃后要用这个值再重新写一次
如果数据库系统采用 Append-Only 的 MVCC(多版本并发控制)机制,就不需要传统 WAL 的 UNDO/REDO 记录了。
PostgreSQL 就使用一种近似 append-only MVCC 的方式。它每次修改不是覆盖原值,而是插入一行新版本。因为旧版本仍在,就不需要记录 before value(UNDO),恢复时只需要知道哪些新版本有效就行了。
Example
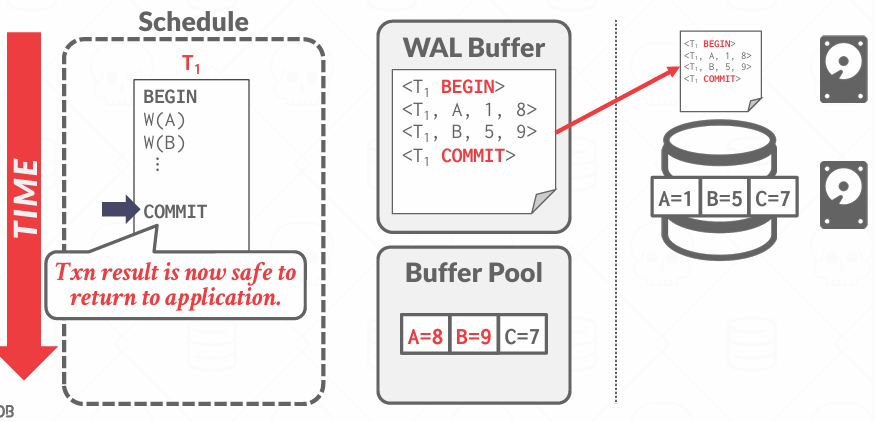
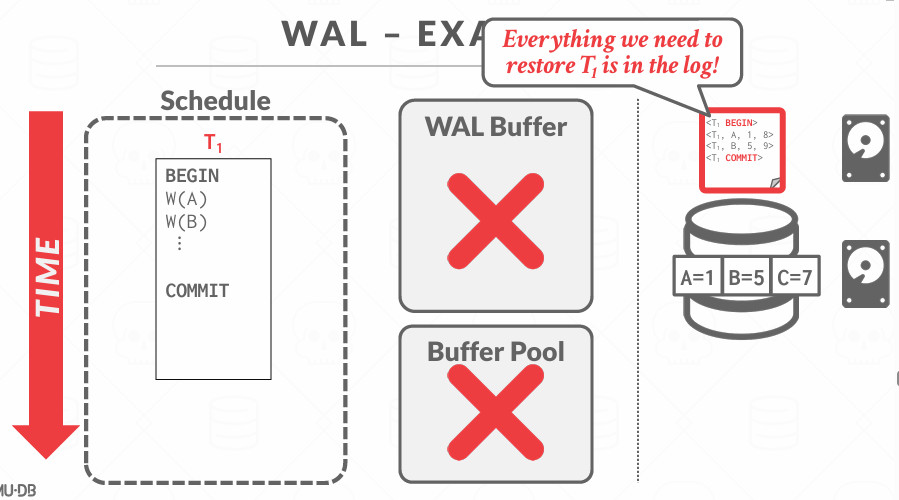
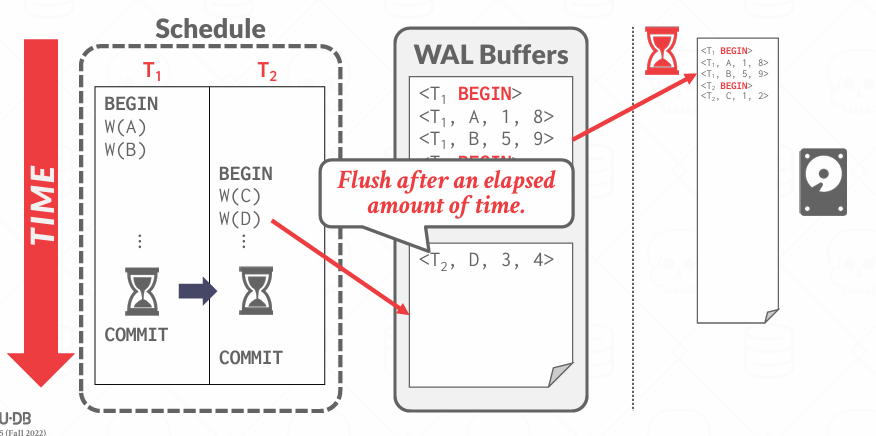
在提交时刻,需要等待那次磁盘IO返回,所以这是slow的
每提交一次都需要等待磁盘操作完成,优化: 大多数系统都会使用一种称为group commit"组提交"的技术,想法很简单,就是把一起到来的提交进行批处理
它的核心思想是:把多个事务的日志写入内存 buffer,集中一次 flush 写入磁盘,从而摊薄(amortize)一次写磁盘的代价。
实现机制: log buffer满了; 没满,过一段时间(eg 5 ms) 也会flush一次
Logging Schemes
存在三种不同的日志记录方案
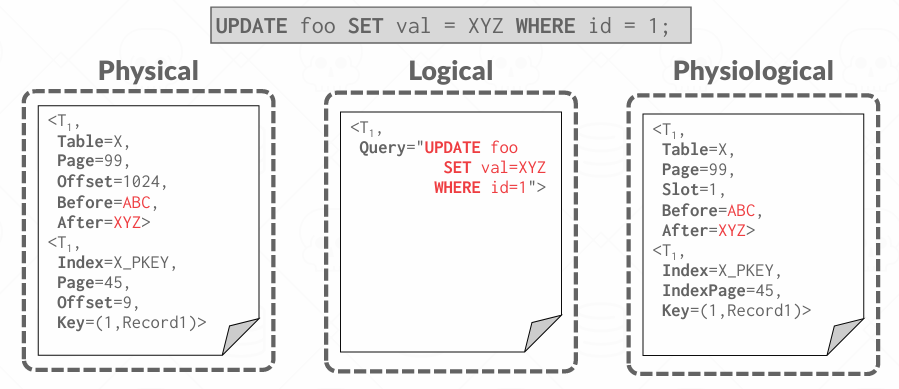
Physical Logging
我要记录的内容实质上类似于一个差异对比: 数据页中具体那几个字节发生了变化, 比如图中的例子精确的记录了数据页Page=99 中的哪个字节(Offset =1024)发生了变化,变化之前是ABC,变化之后是XYZ, 后面是事务还更新了该表的主键索引X_PKEY, 也需要记录变化
现在Physical Logging面临的挑战是, 假设我正在操作一个页面,而这个页面采用的是slotted page structure, 记录可以在带有slotted id的页结构中移动,同时保持slot id不变(这个在Lecture 3中我记的是), 在页面中可能会发生压缩,可能offset就不准了,这就引出了我们要用Physiological Logging
Physiological Logging
日志中仍然定位到某个物理页(page id),但在页内部使用 slot id 来定位 tuple,而不是字节 offset
Physical-to-a-page, logical-within-a-page
Logical Logging
另一种极端是Logical Logging, 记录的事务执行的语义操作,而不是哪些哪些字节发生了变化
Log-Structured Systems
log-structured DBMSs只是与heap file organization一种不同的组织方式,在前面的Lecture中我们见过,对于log-structured filesystems 大多数都有类似于内存表的东西叫MemTable,保持在内存中,记录变化,并最终会达到日志结构化文件的下层。但在这一段时间,实际数据还是会停留在内存,然后才会被写入。
如果发生崩溃,我们实际上使用恢复和日志机制来保护内存表,并能够恢复它 跟之前并没有两样
不过Log-Structured系统中没有dirty pages,所以不涉及
Checkpoints
WAL会不断变大
当数据库崩溃的时候,需要重新建WAL中的日志执行一遍,如果WAL很长,则意味着恢复过程十分耗时
有一种机制叫Checkout,清理掉老的WAL日志,这时候崩溃时不需要从头开始重放WAL, 只需要从上一个checkpoint开始
接下来我们将讨论进行Checkpoint的不同方法,但主要观点是,我们将创建一个新的日志记录,成为检查点记录,我们会常见一个开始检查点和一个结束检查点记录,为了使得检查点方法更加简单优化,我们研究了一系列算法。
从非常高层次来看,简单的Checkpoint是暂停所有正在运行的查询和事务,将WAL的日志写入磁盘,然后将所有修改过的page刷新到磁盘,然后写入检查点,但是可能缓冲池很大,并且大部分页面是脏页,那么这个检查点本身还是会耗费很长时间,因此,后面我们会探讨如何进行改进(下一个lecture?)

存在一个问题是:我应该多频繁的进行检查点操作?
我们希望该操作尽可能小,但是仍需要执行一定的工作,而且不能在短时间内频繁暂停事务
大多数数据库系统提供了参数,自行可以设置 这是需要一个权衡的点